以往的Blender 3D设计工作流,就是网格建模、着色器上色和渲染这“三板斧”,大多数情况下,即便是比较简单的模型设计,时间成本也是以小时为单位来进行计算,画大半天来做一个中等精度的模型都算是效率很高了。
不过,随着AI技术的不断加强,现在完全可以借助人工智能工具来降低门槛、加快速度,本期我们就让Liblib在线文生图平台、Unique3D在线D模型平台和Blender“三强联手”,看看AI加持之下的3D设计有多么高效。
Liblib是一个AI在线文生图平台(网址:),网站注册很简单,微信就能直接绑定账号,非付费会员每天有300点算力,一张512×512级别的图像生成需要1点算力,一张1024×1024级别的图像生成需要2点算力,有大量的模型库可以浏览,也可以把感兴趣的模型添加到自己的模型库里在生成时调用,当然,有部分模型是付费会员专属。
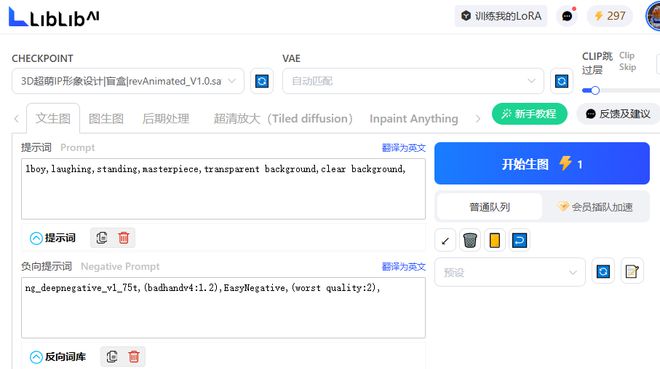
在添加完模型之后,我们点击主页左侧的“在线生图”进入文生图界面,从UI来看和Stable Diffusion基本一致,所以如果你有Stable Diffusion使用经验的话很容易就能上手。
如图1所示,在左上角“CHECKPOINT”选项选择你想要生成的模型,然后在“提示词”页面输入提示词,比如我们用“1boy,laughing,standing,masterpiece,transparent background,clear background”作为关键词,也就是一个“站着露出笑脸的男孩,透明的背景,干净的背景”,Liblib也支持在线翻译,所以大家可以直接写中文,点一下“翻译成英文”就可以了。“负向提示词”它会自动载入几个最常用的关键词,所以直接用默认的就行。
接下来设置采样方法,最好是选择模型作者推荐的方法,对于大多数模型来说,图像长和宽尽量不要超过768,比如我们设置为,512×768,就是想要得到一个全身像而已。

设置完成后点击“开始生图”,旁边有需要的算力点数,接下来就是排队等待分配算力,正常情况下一两分钟就能完成渲染,比如本教程就得到了如图2的最终效果,将它另存到电脑硬盘里。
当我们得到平面图像之后,下一步就是将它从2D图片变成3D模型了,最近有一款免费的Unique3D应用火遍全网,它的主要用途就是将用户上传的照片转换为3D模型,而且和Liblib一样基于Webui交互,用户只需要打开在线生成平台的链接上传图片、等待排队渲染即可,甚至连用户注册都省略了……
而且,这个性能相当强悍的3D模型生成器其实源自咱们清华大学的00后研发团队AiuniAI,模型在github、wisemodel和Huggingface等平台已经开源,一上线就登上了Huggingface的热门模型排行榜,还被旗下官方工具Gradio在海外媒体上提名为“最佳图片生成3D模型”。
算法方面,Unique3D提出了创新的多视图扩散和多级分辨率提升的模型及重建算法,具有目前可用的最高精度和高一致性的几何与材质。不过需要注意的是,投喂给它的图像必须有相对干净的背景,而且官方建议最好是角色摆T字造型的正视图,否则可能出现比较明显的生成错误,比如不应该存在的顶点,有时候甚至会直接报错。
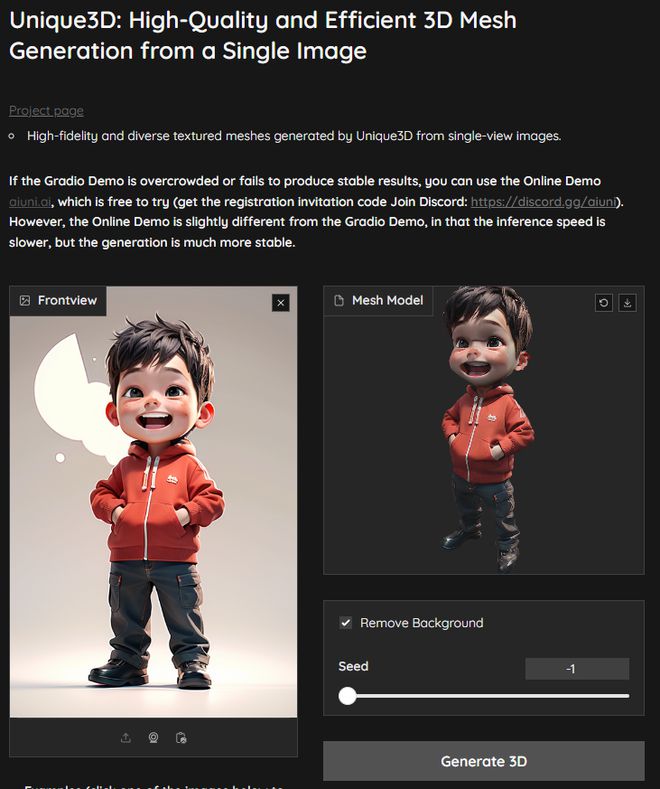
我们用Liblib生成的图片在Unique3D里可以获得如图3的效果,可以通过拖拽鼠标来旋转模型,也可以通过鼠标滚轮来缩放检查,不满意的话还可以重新生成,完成后点击生成界面右上角的↓箭头,将.glb格式的3D文件下载到本地硬盘上。当然,如果你的电脑性能较强,且有安装Linux系统,也可以将模型下载到本地部署,使用本地算力进行生成。
得到模型之后,我们打开Blender,在“文件”、“导入”菜单找到.glb格式选项,将刚刚生成的小孩模型导入到Blender里,我们就能看到如图4的模型被正确导入到3D视图区域内了。
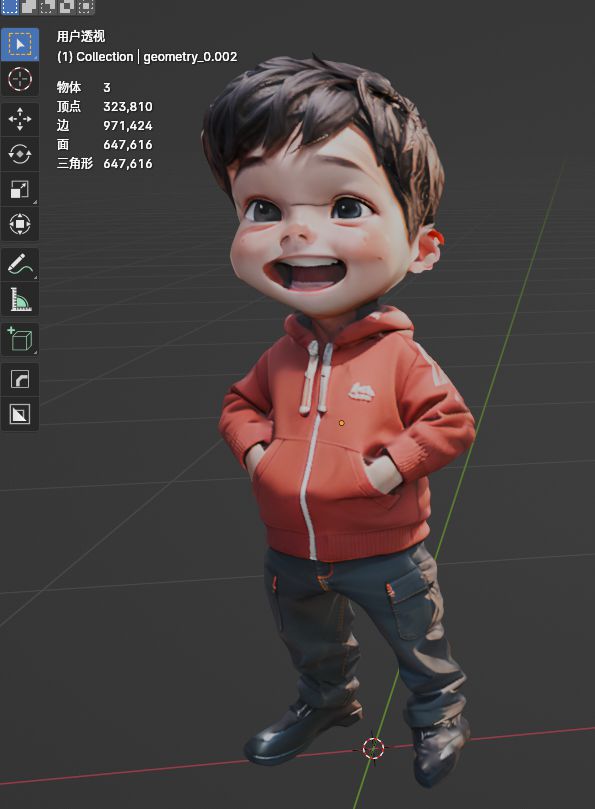
可以看到,整个模型根据照片的颜色进行了着色,而且旋转到模型背部,也可以发现它生成了原图中并不存在的帽衫帽子部分,效果确实不错。但同时也不难发现存在大量问题,比如因为原图的小孩是侧面站立,所以它的3D模型侧面存在明显的透视错误,导致面部存在塌陷和错位等问题,稍微调整一下视角就能察觉出问题。除此之外模型背部也有不少额外生成的错误模型,这些部分都需要在Blender里进行调整。
大多数情况下Unique3D生成的模型精度都比较高,为了提高设计效率,我们可以先用“精简”修改器减少模型的顶点数量,比如本案例就将原本的32.3万个顶点缩减到了12.8万个顶点,同时保证视觉上很难看出区别。
然后进入编辑模式,删除不需要的顶点区域,让模型可以正常化显示。接下来进入雕刻模式,使用抓起、平滑、自由线等笔刷工具对模型头部和面部各个错误区域进行调整,最终我们需要得到如图5的效果,可以看到调整后的模型(左)头部比例比原始模型(右)要正常了不少,对于部分特定场景来说已经达到堪用的水准。

在熟练掌握使用技巧外加运气较好的情况下,10分钟完成这一套工作流没有任何问题,不过从最终效果来看,这套工作流其实更适合用来制作场景物体,比如我们做的这个小男孩,如果作为设计主体,那要修改的地方可就太多了,不仅需要对模型进行大量的重新雕刻,还因为原始图片自带光影的缘故,加之现阶段的文生图大模型分辨率比较低,所以贴图材质也不能直接使用,需要手动重绘……
综上所述,这种快速工作流还无法替代正统的建模流程,但如果你要制作一个大场景,需要大量填充背景环境的人物、动物、怪兽等模型物体,那么因为这些物体都不会占据主视角,稍微有点瑕疵也没有问题,使用这个工作流就可以节约大量时间,让设计师将注意力放在视觉焦点物体上,更高效地完成工作。

壹零社:用图文、视频记录科技互联网新鲜事、电商生活、云计算、ICT领域、消费电子,商业故事。《中国知网》每周全文收录;中国科技报刊100强;2021年微博百万粉丝俱乐部成员;2022年抖音优质科技内容创作者










暂无评论
发表评论